Ethical Considerations In Data Science: A Python Approach


Ethics in data science is the responsible, fair, and honest use of data. It involves protecting people’s privacy, preventing data misuse, and ensuring transparency in data collection, processing, and analysis. In today's world, where data-driven decision-making is needed in industries like healthcare and finance, ethical considerations have become more crucial than ever. Such decisions carry significant consequences, influencing lives, livelihoods, and societal structures.
Common Ethical Concerns in Data science include:
Data Privacy: Protecting sensitive information from misuse or unauthorized access.
Fairness: Ensuring that models do not discriminate against individuals or groups based on bias in the data.
Accountability: Defining responsibility for the outcomes of automated systems.
Transparency: Making models interpretable and explainable makes their decisions understandable to stakeholders.
We’ll be using a Python-based case study to explore ethical issues and offer solutions.
Hypothetical Scenario: Loan Approval Model for a Bank
Imagine that a bank develops a model to automate loan approvals. The model is trained on historical data, which includes sensitive features such as age, gender, financial histories, loan repayment statuses, and so on.
While this data is used to streamline the decision-making process and improve efficiency, several ethical dilemmas arise such as:
Risk of Bias in Predictions:
The training data may reflect historical societal biases or imbalances. For instance, if past loan approvals disproportionately favored certain age groups, genders, or income brackets, the model could inherit and perpetuate these biases. As a result, qualified applicants from underrepresented groups may face unfair denials.Use of Sensitive Features:
Including sensitive features like age and gender in the model raises questions about fairness and discrimination. Even if these features are excluded from the model, their influence might still be indirectly captured through correlated variables (e.g., occupation or education level).Imbalanced Training Data:
If the training dataset is imbalanced, for example, containing significantly more data for high-income applicants than low-income ones, the model may perform poorly for underrepresented groups, leading to unfair outcomes.Lack of Transparency:
Customers denied loans may not understand why their application was rejected, especially if the model is complex or opaque. This lack of transparency can undermine trust in the system and raise compliance issues in jurisdictions requiring explainability.Accountability:
When the model makes biased or incorrect decisions, determining accountability becomes challenging. Is it the responsibility of the data scientists who built the model, the institution deploying it, or the individuals overseeing the data pipeline?
How can we incorporate ethical considerations into decision-making?
Data privacy:
a. Anonymize or pseudonymize data where possible: Collecting and storing excessive personal information can lead to security vulnerabilities, breaches, or violations of privacy regulations like GDPR or CCPA.
i. Replace sensitive identifiers (e.g., names, ID numbers) with pseudonyms or hashed values
ii. Aggregate data to remove individual-level details where fine-grained analysis is not necessary.
b. Minimize Data Collection:
i. Collect only the data necessary for the task. Avoid retaining sensitive data longer than required.
c. Secure Data Handling:
I. Encrypt sensitive data during storage and transmission.
ii. Limit access to sensitive information based on roles and permissions.
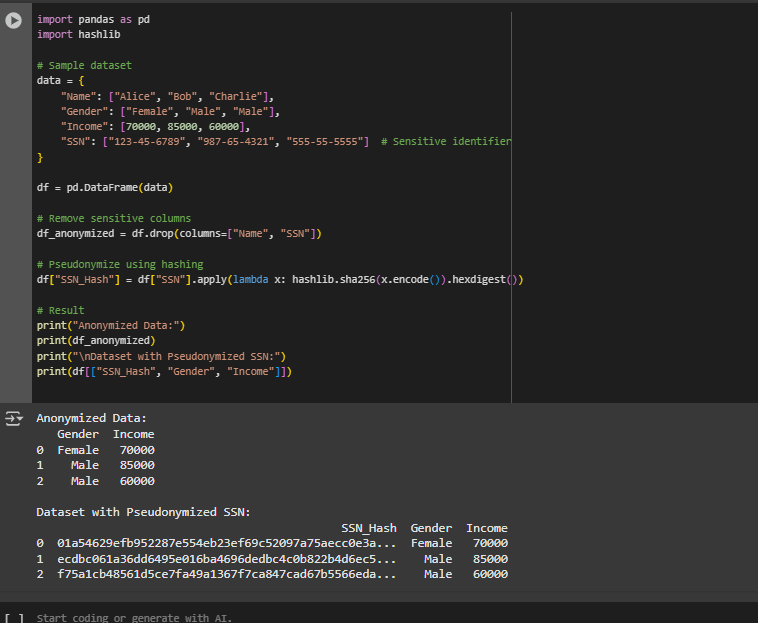
Sensitive identifiers like names and SSNs are either removed or hashed to protect user identities. Hashing ensures that the data is not directly linked to individuals but can still be used for matching records if needed. This approach demonstrates responsible data handling, minimizing the risk of exposure or misuse while maintaining the utility of the dataset.
2. Bias and Fairness problem: Machine learning models can unintentionally inherit and amplify societal biases present in the training data, such as gender or racial discrimination. For example, in the case of loan approval, training the model on biased historical data might unfairly deny loans to certain gender groups, perpetuating inequality.
a. Use fairness metrics
I. Evaluate model predictions using fairness metrics to detect bias
ii. Metrics include disparate impact, demographic parity, equalized odds, and predictive parity.
b. Monitor approval rates across groups
i. Analyze and compare key metrics (e.g. approval rates) for different demographic parity, equalized odds, and predictive party.

The output shows the average loan approval rates for males and females. The significant difference between the groups indicates potential bias in the model.
In cases like this, where bias is detected, consider mitigating it using techniques like re-sampling, re-weighting, or adversarial debiasing to mitigate it. Also, audit models regularly to ensure fairness throughout their lifecycle.
3. Transparency and Explainability: Black-box models like neural networks are highly accurate but lack interpretability, making it difficult to explain how decisions are made. This lack of transparency can lead to mistrust, particularly when decisions like loan denials impact customers' lives. Stakeholders, including customers and regulators, demand clarity about the factors influencing predictions.
a. Use Interpretable Models:
I. Opt for simpler models like decision trees or logistic regression in cases where transparency is crucial. These models are easier to explain and understand.
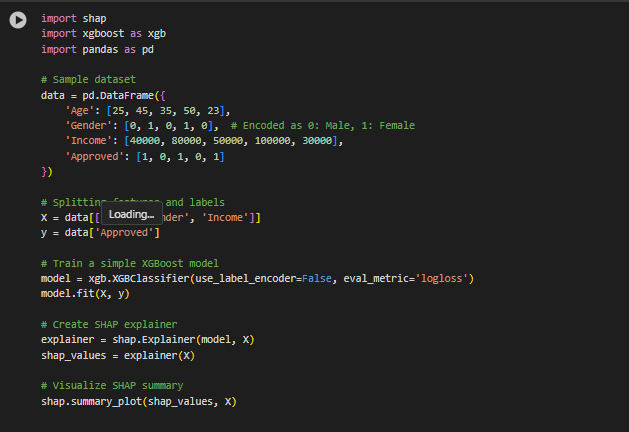
b. Use Explainability Tools for complex models:
i. Employ tools like SHAP (SHapley Additive explanations) or LIME (Local Interpretable Model- agnostic Explanations) to explain predictions of complex models. These tools show how each feature contributes to the final prediction, making the decision process transparent
4. Accountability: Automated systems often make decisions that can significantly impact individuals, such as denying loans or hiring candidates. When these systems make harmful or unfair decisions, it is often unclear who is responsible— the developer, the organization, or the model itself. This lack of accountability erodes trust and prevents corrective action.
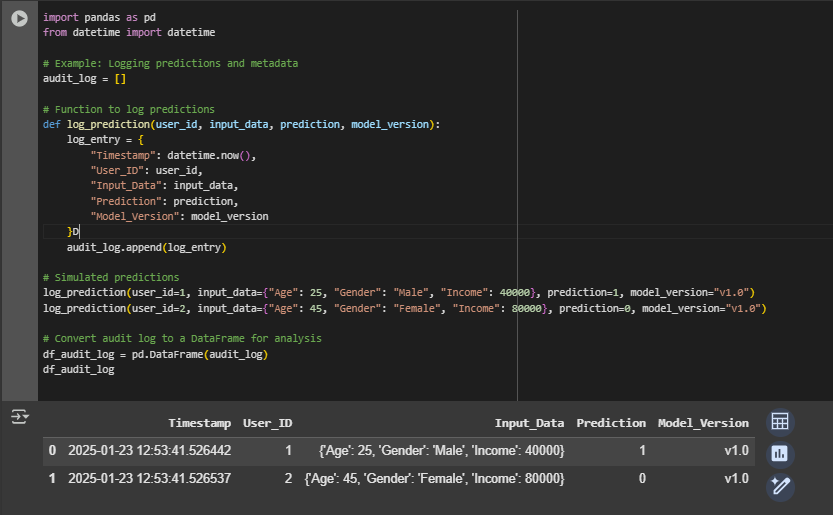
a. Maintain Audit Logs:
I. Record details of all predictions made by the model to allow tracking and investigation of decisions.
b. Track Metadata:
I. Store information about the model, including:
Model Versions: To track changes over time.
Training Datasets: To ensure reproducibility and identify potential biases.
Performance Metrics: To monitor how the model evolves and performs across different scenarios.
Ethical considerations are at the core of responsible data science. Proactive measures, such as anonymizing data, using fairness metrics, leveraging explainability tools like SHAP, and maintaining detailed model logs, are essential in ensuring ethical practices in data science. These actions foster trust among stakeholders and also help to meet regulatory requirements and societal expectations.
As data scientists, it's vital to prioritize ethics alongside technical accuracy. By embedding ethical principles into every stage of the data science lifecycle from data collection to model deployment, we can ensure that our work benefits individuals and society while minimizing harm.